지난 포스팅에서 동시성 문제 해결 방법으로 Synchronized에 대해서 알아보았다. Synchronized를 활용한 동시성 해결은 분산 환경에서는 활용될 수 없다. 이번 포스팅에서는 데이터 베이스 Lock, 레디스를 활용한 분산락을 통해 동시성을 해결하는 방법에 대해서 알아보고자 한다.
✔️ Pessimistic Lock 활용 - Database Level
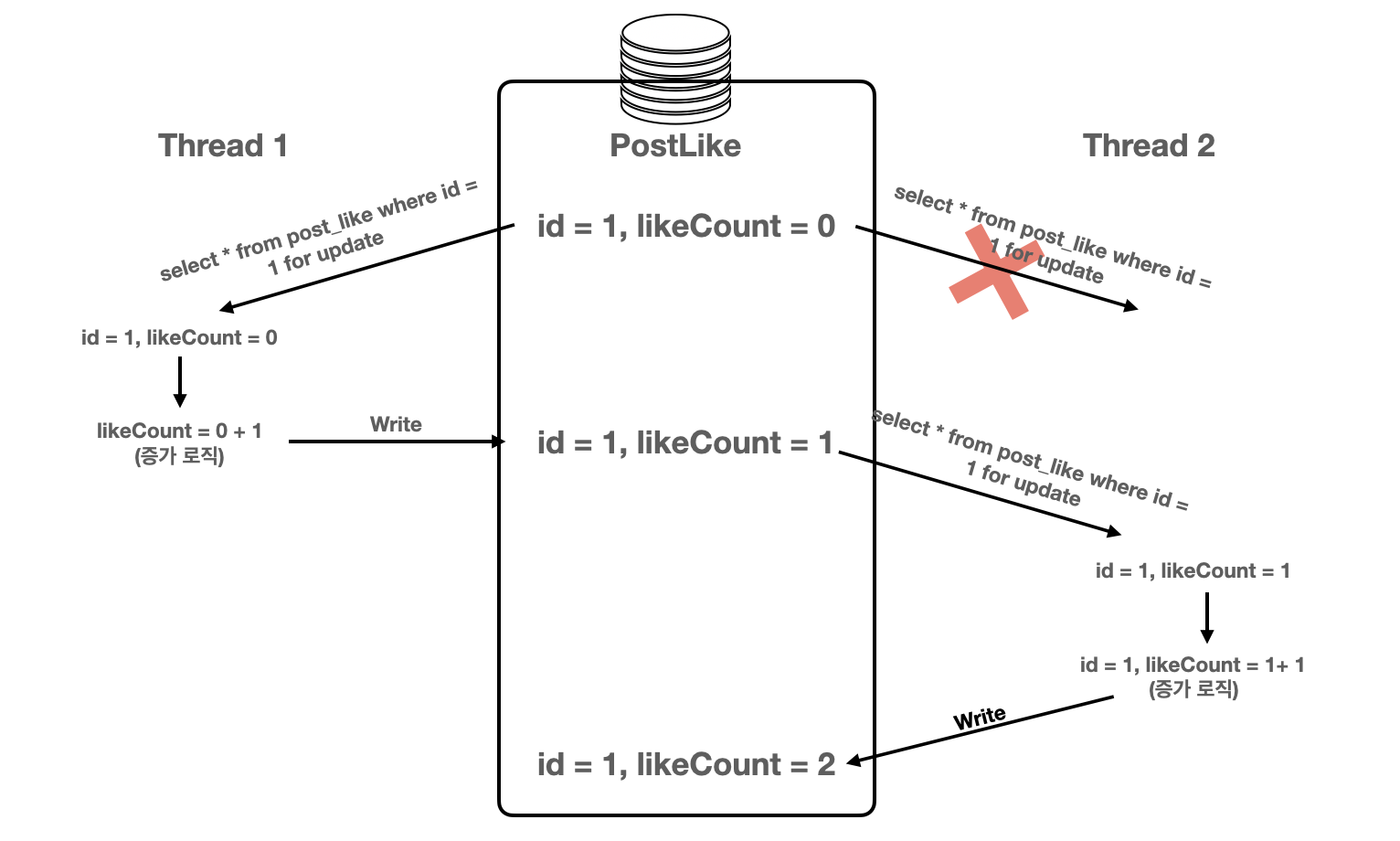
데이터 베이스에서 지원하는 Pessimistic Lock(비관적 락)을 활용하여 실제 데이터 베이스에 Exclusive Lock을 걸어서 데이터 정합성을 보장할 수 있다.
🔗 Exclusive Lock
배타적 잠금, 쓰기 잠금이라고 불린다. 한 트랜잭션에서 데이터를 변경하거나 쓰고자 할 때, 해당 트랜잭션이 완료될 때까지 레코드(row), 테이블(table) 수준에 락을 걸어서 다른 트랜잭션에서 읽거나 쓰지 못하도록 하는 락의 종류이다. 기본적으로 exclusive lock을 걸면 shared lock과 다른 트랜잭션에서 exclusive lock을 걸 수 없다.
@Repository
interface PostLikeRepository : JpaRepository<PostLike, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select pl from PostLike pl where pl.id = :postLikeId")
fun findByPostIdWithPessimisticLock(postLikeId: Long): PostLike
}JPA를 사용하면 @Lock 어노테이션을 사용하여 LockModeType을 PESSIMISTIC_WRITE로 설정하여 Pessimistic Lock을 활용한 조회를 한다. 다른 트랜잭션에서 조회한 데이터를 읽거나 쓸 수 없다.
🔗 LockModeType
OPTIMISTIC: 낙관적 락으로 트랜잭션 시작 시 버전 점검이 수행되고, 트랜잭션 종료 시에도 버전 점검이 수행된다.
OPTIMISTIC_FORCE_INCREMENT: 낙관적 락을 사용하면서, 추가로 버전을 강제로 증가시키는 방법
PESSIMISTIC_READ: 비관적락을 사용하면서, 다른 트랜잭션에게 읽기만 허용한다. (Shared Lock을 건다)
PESSIMISTIC_WRITE: 비관적락을 사용하면서, Exclusive Lock을 이용해서 락을 건다. 다른 트랜잭션에서 쓰지도 읽지도 못한다.
PESSIMISTIC_FORCE_INCREMENT: Exclusive Lock을 이용해서 락을 걸고 동시에 버전을 증가시킨다.
@Service
class PessimisticLockPostLikeService(
private val postLikeRepository: PostLikeRepository,
) {
@Transactional
fun increase(postLikeId: Long) {
val postLike = postLikeRepository.findByPostIdWithPessimisticLock(postLikeId)
postLike.increase()
}
}@Test
fun `멀티 스레드 환경에서 동시에 총 100개의 좋아요 증가 요청이 들어오면, 좋아요 수는 100이다`() {
// given
val postLike = postLikeRepository.save(PostLike(postId = 1L, likeCount = 0L))
val threadCount = 100
val executorService = Executors.newFixedThreadPool(20)
val countDownLatch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executorService.submit {
try {
pessimisticLockPostLikeService.increase(postLike.id)
} finally {
countDownLatch.countDown()
}
}
}
countDownLatch.await()
val findPostView = postLikeRepository.getReferenceById(postLike.id)
// then
assertThat(findPostView.likeCount).isEqualTo(100)
}Pessimistic Lock을 사용한 Service와 Service에 대한 테스트 코드를 작성하고 실제 테스트를 수행한다.


PostLike를 조회할 때, for update가 쿼리에 추가되는 것을 통해 exclusive lock이 사용되는 것을 확인할 수 있다. 실제 테스트의 결과도 성공하는 것을 확인할 수 있다.
📝 Pessimistic Lock 사용 시, 다중 서버에서의 동시성 보장 확인


@RestController
@RequestMapping("/api/v1/post-likes")
class PostLikeController(
private val pessimisticLockPostLikeService: PessimisticLockPostLikeService
) {
@PostMapping("/{postLikeId}/increase")
fun increasePostLike(
@PathVariable("postLikeId") postLikeId: Long,
): ResponseEntity<Void> {
pessimisticLockPostLikeService.increase(postLikeId)
return ResponseEntity.noContent().build()
}
}환경을 설정하고 PessimisticLockPostLikeService를 사용하는 Controller를 생성한뒤, 실제 테스트를 진행한다.


테스트 결과 정상적으로 좋아요 수가 400으로 증가 되어 있는 것을 확인할 수 있고, 에러 없이 요청의 평균 시간은 0.022초 소요된 것을 확인할 수 있다.
✏️ Pessimistic Lock은 Lock을 통해서 데이터를 제어하기 때문에, 데이터의 정합성은 보장되지만 Lock을 사용하는 만큼 성능이 안 좋을 수 있다.
✔️ Optimistic Lock 활용 - Application Level
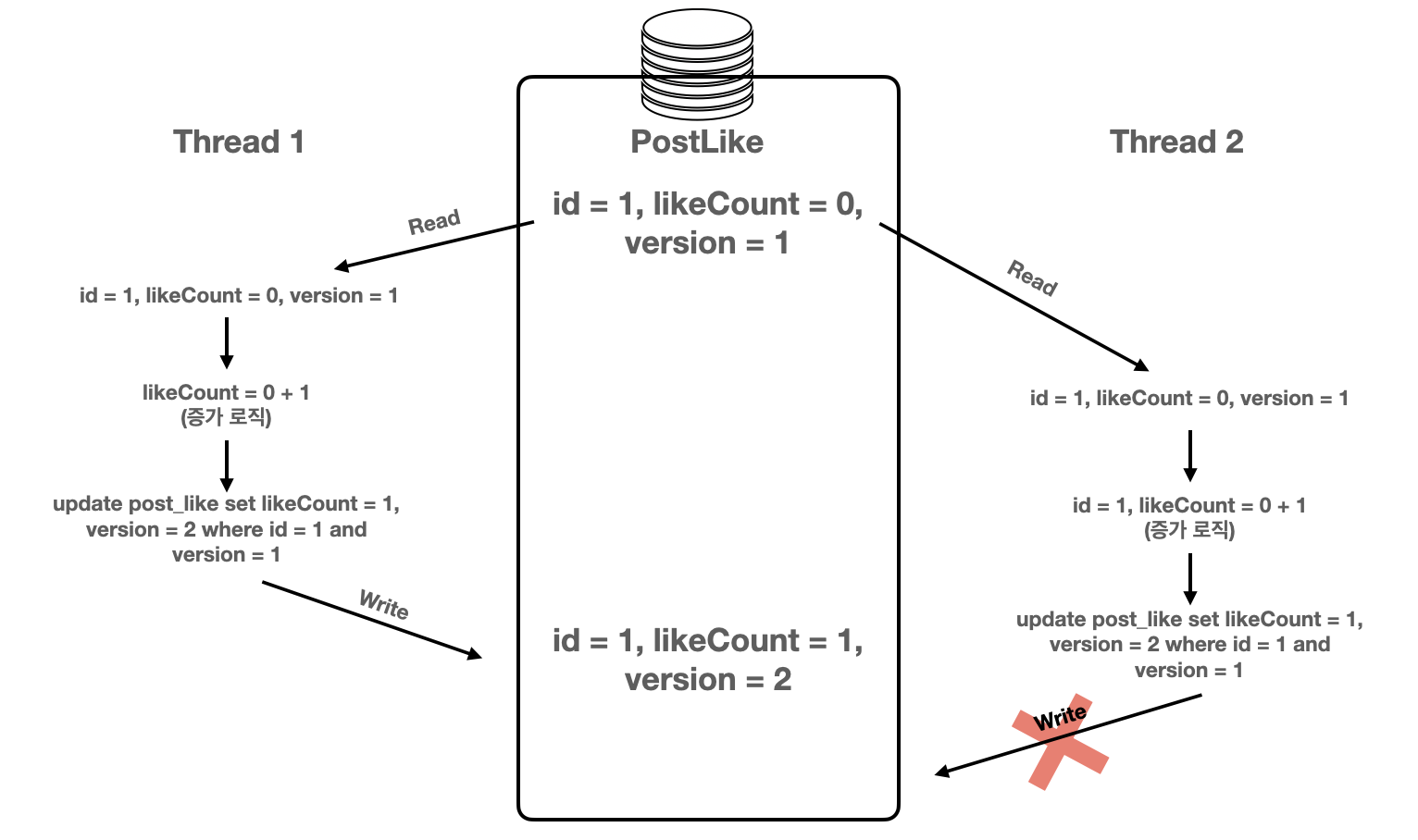
실제 데이터 베이스의 Lock을 사용하지 않고, 버전 등의 구분 칼럼을 사용해서 정합성을 맞추는 방법이다. 데이터를 읽은 후, 업데이트를 수행할 때 읽었던 버전을 where 절에 추가하여 데이터를 확인하여 업데이트를 진행한다. 만일 다른 스레드에 의해 버전이 증가하였고, 현재 스레드의 버전 값이 데이터 베이스의 데이터 버전과 일치하지 않는다면 실패한다.
Optimistic Lock을 활용하면, 개발자는 버전 불일치로 인한 실패 시 어떻게 대응할 것인지 예외(복구) 로직을 작성해야 한다.
@Entity
class PostLike(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0L,
@Column(nullable = false)
val postId: Long,
@Version
val version: Long = 0L,
likeCount: Long,
) {
@Column(nullable = false)
var likeCount: Long = likeCount
private set
fun increase() {
this.likeCount += DEFAULT_INCREASED_LIKE_COUNT
}
}JPA를 사용하면 @Version 어노테이션을 사용해서, 간단하게 버전 필드 생성 및 Optimistic Lock을 사용할 수 있다.
@Repository
interface PostLikeRepository : JpaRepository<PostLike, Long> {
@Lock(LockModeType.OPTIMISTIC)
@Query("select pl from PostLike pl where pl.id = :postLikeId")
fun findByPostIdWithOptimisticLock(postLikeId: Long): PostLike
}LockModeType을 OPTIMISTIC으로 지정하여 Optimistic Lock을 활용하여 데이터를 조회한다.
@Service
class OptimisticLockPostLikeService(
private val postLikeRepository: PostLikeRepository,
) {
@Transactional
fun increase(postLikeId: Long) {
val postLike = postLikeRepository.findByPostIdWithOptimisticLock(postLikeId)
postLike.increase()
}
}@Component
class OptimisticLockPostLikeFacade(
private val optimisticLockPostLikeService: OptimisticLockPostLikeService,
) {
fun increase(postLikeId: Long) {
while (true) {
try {
optimisticLockPostLikeService.increase(postLikeId)
break
} catch (exception: OptimisticLockingFailureException) {
Thread.sleep(50)
}
}
}
}좋아요 update를 진행할 때, 버전이 불일치하면 org.springframework.dao.OptimisticLockingFailureException 예외가 발생한다. OptimisticLockingFailureException 예외를 Catch하여 재시도 로직을 작성하기 위해 Facade 서비스를 생성하였다. 현재 로직에서는 버전 불일치로 인한 로직 실패 시, 0.05초 후에 재시도한다.
@Test
fun `멀티 스레드 환경에서 동시에 총 100개의 좋아요 증가 요청이 들어오면, 좋아요 수는 100이다`() {
// given
val postLike = postLikeRepository.save(PostLike(postId = 1L, likeCount = 0L))
val threadCount = 100
val executorService = Executors.newFixedThreadPool(20)
val countDownLatch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executorService.submit {
try {
optimisticLockPostLikeFacade.increase(postLike.id)
} finally {
countDownLatch.countDown()
}
}
}
countDownLatch.await()
val findPostView = postLikeRepository.getReferenceById(postLike.id)
// then
Assertions.assertThat(findPostView.likeCount).isEqualTo(100)
}

실제 테스트를 수행하면, 예외가 발생하여 Thread.sleep()이 수행되는 것을 확인할 수 있고 테스트도 정상 완료된다.
📝 Optimistic Lock 사용 시, 다중 서버에서의 동시성 보장 확인
@RestController
@RequestMapping("/api/v1/post-likes")
class PostLikeController(
private val optimisticLockPostLikeFacade: OptimisticLockPostLikeFacade
) {
@PostMapping("/{postLikeId}/increase")
fun increasePostLike(
@PathVariable("postLikeId") postLikeId: Long,
): ResponseEntity<Void> {
optimisticLockPostLikeFacade.increase(postLikeId)
return ResponseEntity.noContent().build()
}
}환경을 설정하고 OptimisticLockPostViewFacade를 사용하는 Controller를 생성한 뒤, 실제 테스트를 진행한다.
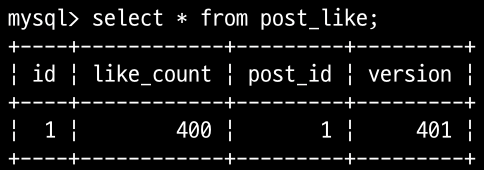

테스트 결과 정상적으로 좋아요 수가 400으로 증가 되어 있는 것을 확인할 수 있고, 에러 없이 요청의 평균 시간은 0.030초 소요된 것을 확인할 수 있다.
✏️ Optimistic Lock은 별도의 Lock을 잡지 않아서 성능 상 장점이 있을 수 있지만, 업데이트가 실패하면 개발자가 직접 복구 로직을 작성해야 한다는 번거로움과 충돌이 빈번하면 복구 로직으로 인해 오히려 성능이 안 좋아진다는 단점이 존재한다.
🤔 Pessimistic Lock과 Optimistic Lock 중 어느 것을 사용할까?
두 Lock 중 어느 것을 활용하면 좋다는 것에 대한 정답은 없다. (데이터 베이스 서버의 성능 고려, 트래픽 등 고려해야 할 사항이 많다.) 단순하게 고려해 봤을 경우에는 위 테스트 결과를 통해 확인해 볼 수 있듯이, 만일 충돌이 빈번하면 복구 로직으로 인해 평균 응답 속도가 증가한 Optimistic Lock 대신 Pessimistic Lock을 사용하는 것이 좋고 충돌이 빈번하지 않다면 실제 데이터 베이스 데이터에 락을 거는 것이 아닌 Optimistic Lock을 사용하는 것이 좋다.
✔️ Named Lock 활용 - Database Level
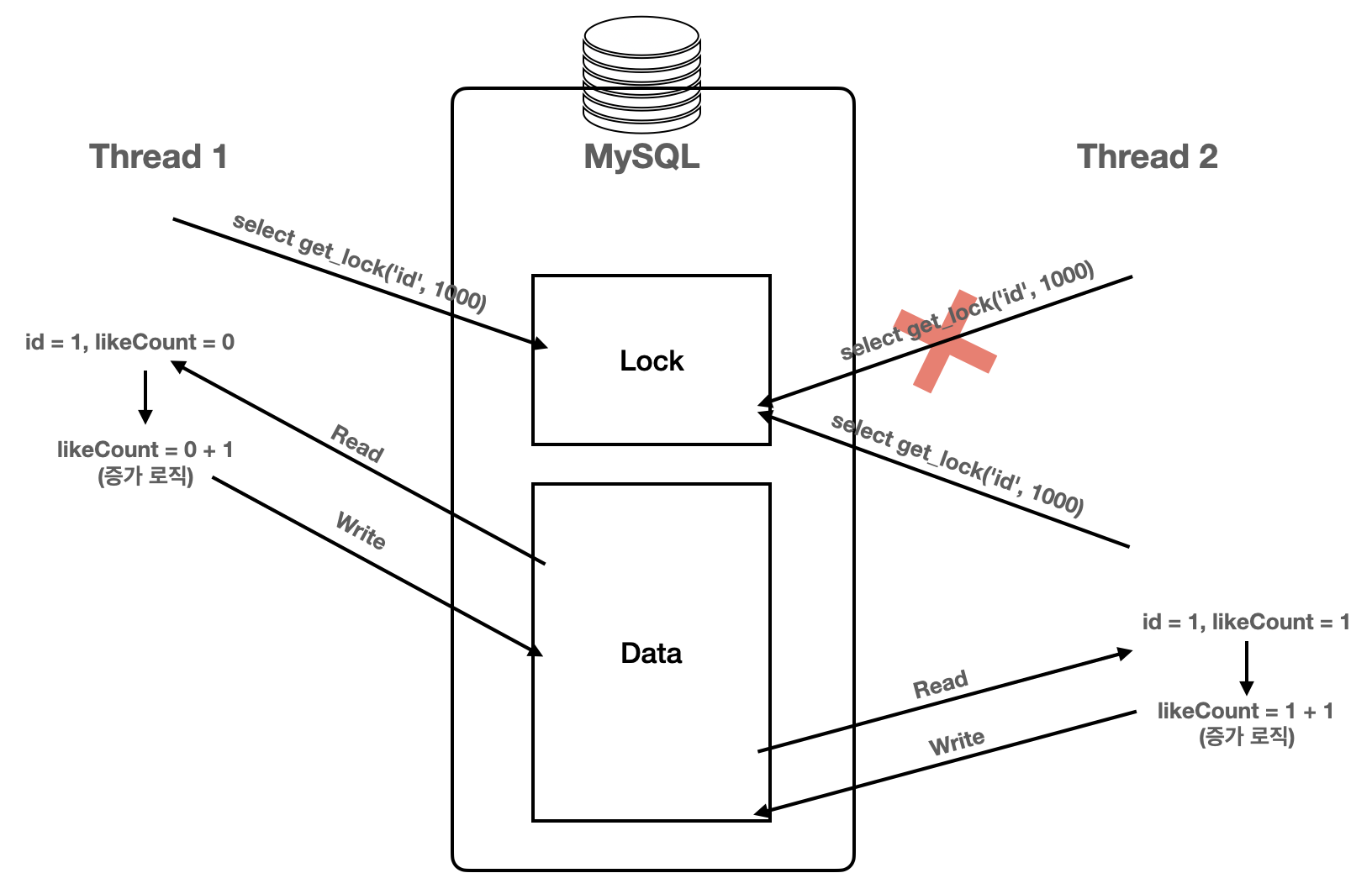
Named Lock은 이름을 가진 metadata locking이다. 이름을 가진 lock을 획득한 후 해제할 때까지 다른 트랜잭션에서는 해당 lock을 획득할 수 없도록해 동시성을 보장한다. Named Lock을 사용하면 트랜잭션이 종료될 때 자동으로 Lock을 해제하지 않아 개발자가 직접 트랜잭션 종료 시 Lock을 해제해주거나, 설정했던 선점 시간이 종료되어야 자동으로 해제된다.
Pessimisitic Lock과 다르게 레코드(row)나 테이블(table)에 락을 거는 것이 아니라 metadata에 Lock을 건다. 데이터에 대한 Lock이 아닌, metadata Lock을 사용하므로 별도의 DataSource를 설정해서 사용해야 실제 서버에서 사용하는 데이터에 접근할 수 있는 데이터 베이스 커넥션 부족 문제를 해결할 수 있다.
@Repository
interface NamedLockRepository : JpaRepository<PostLike, Long> {
@Query(value = "select get_lock(:key, :timeout)", nativeQuery = true)
fun getLock(key: String, timeout: String)
@Query(value = "select release_lock(:key)", nativeQuery = true)
fun releaseLock(key: String)
}Named Lock을 가져오는 Repsitory이다. 테스트를 위한 환경으로 JpaRepository<PostLike, Long>을 구현하여 사용했지만, 실제로는 Named Lock을 가져오는 JDBC 등의 라이브러리를 사용하는 것이 좋다.
@Service
class PostLikeService(
private val postLikeRepository: PostLikeRepository,
) {
@Transactional(propagation = Propagation.REQUIRES_NEW)
fun increaseWithNamedLock(postLikeId: Long) {
val postLike = postLikeRepository.findById(postLikeId).orElseThrow {
NoSuchElementException("postLike not found")
}
postLike.increase()
}
}좋아요 수를 조회해서 증가시키는 로직이다. Named Lock을 제어하는 커넥션과 실제 로직을 수행하는 커넥션을 분리하기 위해서 Propagation.REQUIRED_NEW 옵션을 사용했다.
@Component
class NamedLockPostLikeFacade(
private val namedLockRepository: NamedLockRepository,
private val postLikeService: PostLikeService,
) {
fun increase(postLikeId: Long) {
try {
namedLockRepository.getLock(postLikeId.toString(), DEFAULT_POST_VIEW_NAMED_LOCK_TIMEOUT_MS.toString())
postLikeService.increaseWithNamedLock(postLikeId)
} finally {
namedLockRepository.releaseLock(postLikeId.toString())
}
}
}Named Lock을 가져오고 해제하는 로직과 좋아요를 증가시키는 로직을 구현하기 위해 Fasade 서비스를 생성하였다.
@Test
fun `멀티 스레드 환경에서 동시에 총 100개의 좋아요 증가 요청이 들어오면, 좋아요 수는 100이다`() {
// given
val postLike = postLikeRepository.save(PostLike(postId = 1L, likeCount = 0L))
val threadCount = 100
val executorService = Executors.newFixedThreadPool(20)
val countDownLatch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executorService.submit {
try {
namedLockPostLikeFacade.increase(postLike.id)
} finally {
countDownLatch.countDown()
}
}
}
countDownLatch.await()
val findPostView = postLikeRepository.getReferenceById(postLike.id)
// then
Assertions.assertThat(findPostView.likeCount).isEqualTo(100)
}

실제 테스트를 진행하면, get_lock()을 통해서 Named Lock을 가져오고 release_lock()을 통해 Lock을 해제하는 것을 확인할 수 있다. 테스트도 정상적으로 완료된다.
📝 Named Lock 사용 시, 다중 서버에서의 동시성 보장 확인
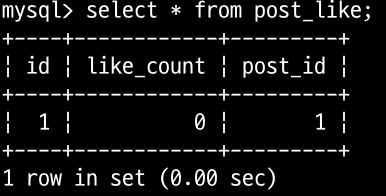
@RestController
@RequestMapping("/api/v1/post-likes")
class PostLikeController(
private val namedLockPostLikeFacade: NamedLockPostLikeFacade
) {
@PostMapping("/{postLikeId}/increase")
fun increasePostLike(
@PathVariable("postLikeId") postLikeId: Long,
): ResponseEntity<Void> {
namedLockPostLikeFacade.increase(postLikeId)
return ResponseEntity.noContent().build()
}
}환경을 설정하고 NamedLockPostLikeFacade를 사용하는 Controller를 생성한 뒤, 실제 테스트를 진행한다.
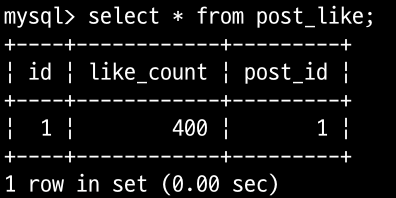

테스트 결과 정상적으로 좋아요 수가 400으로 증가 되어 있는 것을 확인할 수 있고, 에러 없이 요청의 평균 시간은 0.902초 소요된 것을 확인할 수 있다.
✏️ Named Lock은 주로 분산락을 구현하기 위해 사용한다. Named Lock을 사용하게 되면 확실한 분산락을 구현할 수 있지만 개발자 입장에서 구현 과정이 복잡하다.
🔗 분산락
분산락이란 멀티 스레드 환경에서 공유 자원에 접근할 때, 데이터의 정합성을 지키기 위해 사용하는 기술이다.
🤔 Named Lock과 Pessimistic Lock의 차이는 무엇일까?
단일 데이터 베이스 환경이라면, 두 Lock 모두 분산락을 구현할 수 있다. 하지만, 요즘 데이터 베이스도 분산 환경을 가지고 있다. 데이터 베이스가 분산 환경으로 구성되어 있다면 Pessimistic Lock을 사용해서 분산락을 구현할 수 없다. 또한 Pessimistic Lock은 타임 아웃으로 락을 해제할 수 없다는 단점이 존재한다.
✔️ 데이터 베이스 Lock을 활용한 동시성 해결
데이터 베이스 Lock을 활용한 동시성 해결은 Lock을 사용하기에 결국 디스크 읽고/쓰기가 발생하기 때문에 성능이 느리다는 단점이 존재한다. 데이터 베이스 Lock을 활용한 동시성 해결의 성능을 개선하기 위해 Redis(In-Memory DB)를 활용할 수 있다.
✔️ Redis Lettuce 라이브러리 활용
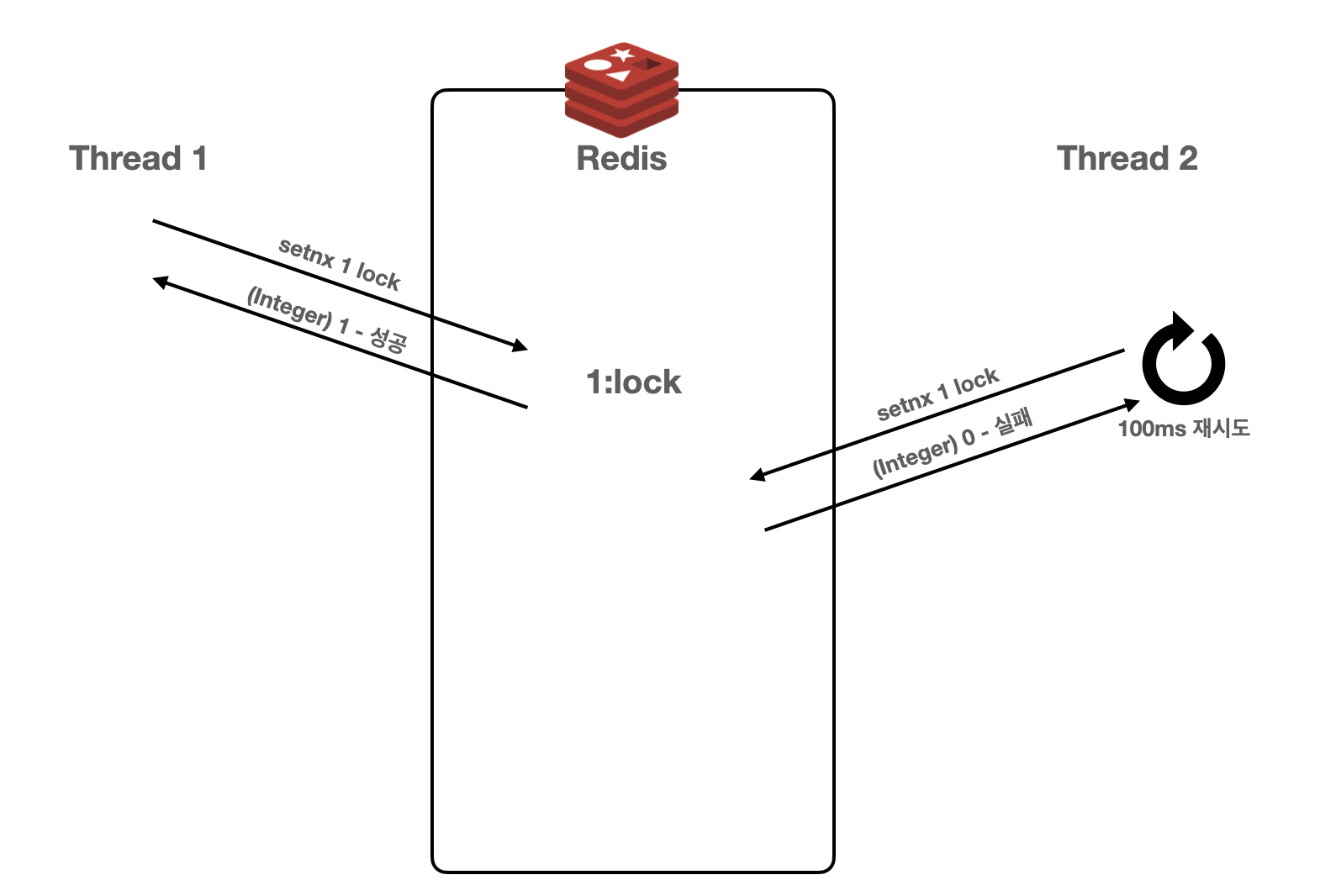
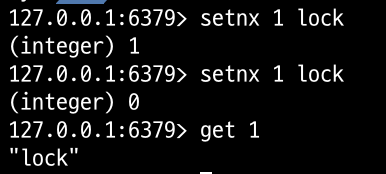
Lettuce 라이브러리를 활용하면 Spin Lock 방식으로 동작한다. 스레드 1이 setnx 명령어를 사용하여 Redis에 데이터 삽입에 성공하면 이후 작업을 진행하고, 스레드 2는 setnx 명령어를 통한 데이터 삽입에 실패하여 삽입이 가능할 때까지 설정한 시간만큼 대기 후 재시도한다.
🔗 Spin Lock
Spin Lock 방식이란 Lock을 획득하려는 스레드가 락을 사용할 수 있는지 반복적으로 확인하면서 Lock을 획득하는 방식이다.
동시에 많은 스레드가 Lock 획득 대기 상태이면 Redis에 부하가 갈 수 있다.
implementation("org.springframework.boot:spring-boot-starter-data-redis")
Spring에서 Redis를 사용하기 위해서 spring-boot-starter-data-redis 의존성을 넣어준다. Default로 Lettuce 라이브러리를 사용한다.
@Component
class RedisLikeRepository(
private val redisTemplate: RedisTemplate<String, String>
) {
fun lock(key: Long): Boolean =
redisTemplate.opsForValue().setIfAbsent(key.toString()), "lock", Duration.ofMillis(DEFAULT_REDIS_LOCK_TIMEOUT_MS)) ?: false
fun unlock(key: Long) {
redisTemplate.delete(key.toString())
}
}redisTemplate를 사용하여 Redis에 데이터를 삽입한다. setIfAbsent()가 setnx 명령어와 동일하게 사용된다.
@Service
class PostLikeService(
private val postLikeRepository: PostLikeRepository,
) {
@Transactional
fun increase(postLikeId: Long) {
val postLike = postLikeRepository.findById(postLikeId).orElseThrow {
NoSuchElementException("PostLike not found")
}
postLike.increase()
}
}@Component
class LettuceLockPostLikeFacade(
private val redisLikeRepository: RedisLikeRepository,
private val postLikeService: PostLikeService,
) {
fun increase(postLikeId: Long) {
while (!redisLikeRepository.lock(postLikeId)) {
Thread.sleep(100)
}
try {
postLikeService.increase(postLikeId)
} finally {
redisLikeRepository.unlock(postLikeId)
}
}
}레디스에 데이터 삽입을 통해 분산락을 구현하기 위한 로직과 좋아요 수를 증가시키는 로직을 Facade 서비스를 생성한다. 데이터 삽입이 성공할 때까지 while 문을 돌고 실패하면 100ms 후 다시 시도한다. 좋아요 증가 로직 수행되면 삽입했던 데이터를 삭제해서 분산락을 구현한다.
@Test
fun `멀티 스레드 환경에서 동시에 총 100개의 좋아요 증가 요청이 들어오면, 좋아요 수는 100이다`() {
// given
val postLike = postLikeRepository.save(PostLike(postId = 1L, likeCount = 0L))
val threadCount = 100
val executorService = Executors.newFixedThreadPool(20)
val countDownLatch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executorService.submit {
try {
lettuceLockPostLikeFacade.increase(postLike.id)
} finally {
countDownLatch.countDown()
}
}
}
countDownLatch.await()
val findPostView = postLikeRepository.getReferenceById(postLike.id)
// then
Assertions.assertThat(findPostView.likeCount).isEqualTo(100)
}
실제 테스트를 진행하면, 성공적으로 완료되는 것을 확인할 수 있다.
📝 Redis Lettuce 사용 시, 다중 서버에서의 동시성 보장 확인
@RestController
@RequestMapping("/api/v1/post-likes")
class PostLikeController(
private val lettuceLockPostLikeFacade: LettuceLockPostLikeFacade
) {
@PostMapping("/{postLikeId}/increase")
fun increasePostLike(
@PathVariable("postLikeId") postLikeId: Long,
): ResponseEntity<Void> {
lettuceLockPostLikeFacade.increase(postLikeId)
return ResponseEntity.noContent().build()
}
}환경을 설정하고 LettuceLockPostLikeFacade를 사용하는 Controller를 생성한 뒤, 실제 테스트를 진행한다.

테스트 결과 정상적으로 좋아요 수가 400으로 증가 되어 있는 것을 확인할 수 있고, 에러 없이 요청의 평균 시간은 0.822초 소요된 것을 확인할 수 있다.
✏️ Lettuce를 활용한 분산락은 구현이 간단하다는 장점이 존재하지만, Spin Lock 방식으로 Redis에 부하를 줄 수 있다.
✔️ Redis Redisson 라이브러리 활용
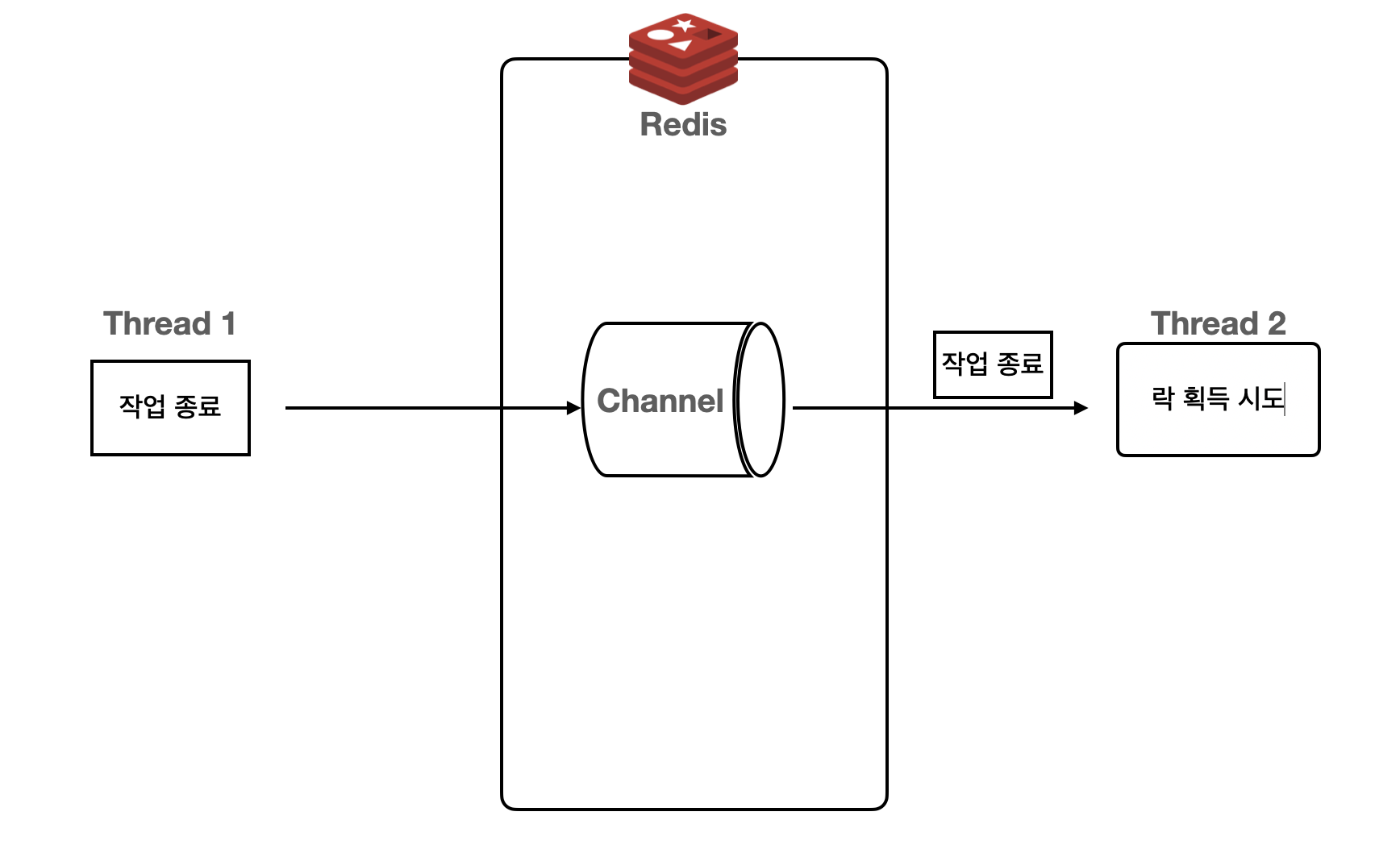
Redisson 라이브러리는 Pub-Sub 기반으로 Lock을 구현할 수 있다. 채널을 구독하고 있는 스레드에게 락을 다 사용하면 메시지를 전달하고, 메시지를 받은 스레드들은 락을 획득하기 위한 작업을 진행한다. 메시지를 받은 다음에 획득을 시도하기 때문에 레디스 부하가 줄어드느다.
📝 Redis-Cli에서 Pub-Sub 사용해보기
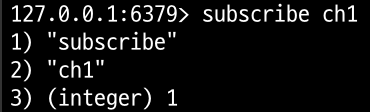
스레드 2번이 channel(ch1)을 구독한다.

스레드 1번이 channel(ch1)에 메시지를 발행한다.
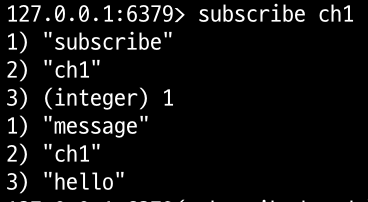
스레드 2번이 메시지를 확인할 수 있다.
implementation("org.redisson:redisson-spring-boot-starter:3.23.4")
Spring에서 Redisson을 사용하기 위해 redisson-spring-boot-starter 의존성을 넣어준다.
@Service
class PostLikeService(
private val postLikeRepository: PostLikeRepository,
) {
@Transactional
fun increase(postLikeId: Long) {
val postLike = postLikeRepository.findById(postLikeId).orElseThrow {
NoSuchElementException("PostLike not found")
}
postLike.increase()
}
}@Component
class RedissonLockPostLikeFacade(
private val redissonClient: RedissonClient,
private val postLikeService: PostLikeService,
) {
fun increase(postId: Long) {
val lock = redissonClient.getLock(postId.toString())
try {
val available = lock.tryLock(10, 1, TimeUnit.SECONDS)
if (!available) {
println("Lock 획득 실패")
return
}
postLikeService.increase(postId)
} finally {
lock.unlock()
}
}
}RedissonClient를 사용해서 Lock을 얻고 해제한다.

tryLock()을 통해 Lock을 얻기 위해 시도한다.
waitTime - Lock 획득을 위해 최대 시간
rentTime - Lock 최대 유지 시간
@Test
fun `멀티 스레드 환경에서 동시에 총 100개의 좋아요 증가 요청이 들어오면, 좋아요 수는 100이다`() {
// given
val postLike = postLikeRepository.save(PostLike(postId = 1L, likeCount = 0L))
val threadCount = 100
val executorService = Executors.newFixedThreadPool(20)
val countDownLatch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executorService.submit {
try {
redissonLockPostLikeFacade.increase(postLike.id)
} finally {
countDownLatch.countDown()
}
}
}
countDownLatch.await()
val findPostView = postLikeRepository.getReferenceById(postLike.id)
// then
Assertions.assertThat(findPostView.likeCount).isEqualTo(100)
}
실제 테스트를 진행하면, 성공적으로 완료하는 것을 확인할 수 있다.
📝 Redis Redisson 사용 시, 다중 서버에서의 동시성 보장 확인
@RequestMapping("/api/v1/post-likes")
class PostLikeController(
private val redissonLockPostLikeFacade: RedissonLockPostLikeFacade
) {
@PostMapping("/{postLikeId}/increase")
fun increasePostLike(
@PathVariable("postLikeId") postLikeId: Long,
): ResponseEntity<Void> {
redissonLockPostLikeFacade.increase(postLikeId)
return ResponseEntity.noContent().build()
}
}환경을 설정하고 RedissonLockPostLikeFacade를 사용하는 Controller를 생성한 뒤, 실제 테스트를 진행한다.

테스트 결과 정상적으로 좋아요 수가 400으로 증가 되어 있는 것을 확인할 수 있고, 에러 없이 요청의 평균 시간은 0.756초 소요된 것을 확인할 수 있다.
✏️ Redisson를 활용한 분산락은 메시지가 올때만 Lock을 획득하려고 한다는 장점이 있지만, 별도의 라이브러리를 사용해야 한다는 단점이 있다.
🤔 Lettuce와 Redisson 중 어느 것을 사용할까?
Lettuce는 spring-data-redis에서 default로 사용하고, 구현이 간단하다는 장점을 가지고 있지만 Spin Lock 방식으로 인해 Redis에 부하를 줄 수 있어 재시도가 필요하지 않은 Lock 방식에 사용하는 것이 적합하고 재시도가 필요한 경우 메시지가 올 때만 시도하는 Redisson이 적합한 것 같다.
'Backend > Spring' 카테고리의 다른 글
| 동시성 문제와 해결 방법들 - 1편 (Synchronized) (1) | 2023.09.06 |
|---|---|
| Spring Event 사용하기 (0) | 2023.06.29 |
| kotlin + HttpInterface 알아보기 (0) | 2023.06.22 |
| Kotlin에서 Rest Docs 문서화 코드 개선하기 (0) | 2023.05.29 |
| Kotest를 통한 DCI 패턴 적용 (0) | 2023.05.27 |



