Partition으로부터 Record(데이터)를 가져와서 활용하는 애플리케이션
- Consumer는 각각의 고유의 속도로 Partition(Commit Log)으로부터 순서대로 Read를 수행한다.
* Consumer Group
- 다른 Consumer Group에 속한 Consumer들은 서로 관련이 없으며(독립적), Partition에 있는 Event(Message)를 동시에 다른 위치에서 Read 할 수 있다.
- Consumer Group은 각 Consumer의 Group Id가 같은 Consumer의 모임이다.
- Consumer Group의 Consumer들은 작업량을 어느 정도 균등하게 분할한다.
* Consumer Offset: Consumer Group이 읽은 위치를 표시한다.

- Consumer가 자동이나 수동으로 데이터를 읽은 위치를 Commit하여 중복 Read를 방지한다.
- __consumer_offsets라는 Internal Topic에 Consumer Offset을 저장하여 관리한다.
- 저장할 때는 다음 읽을 위치를 저장한다. (Offset 2를 읽었으면 3으로 저장)
- Partition은 항상 Consumer Group의 하나의 Consumer에 의해서만 사용되고, Consumer는 주어진 Topic에서 0개 이상의 많은 Partition을 사용할 수 있다.
* Record(Message) Ordering
- 하나의 Topic에 Partition이 2개 이상인 경우, 모든 Record에 대한 전체 순서 보장이 불가능하다.
- Partition을 1개로 만들 경우, 전체 순서 보장이 가능하다. -> 처리량 저하
- 동일한 Key를 가진 Record는 동일한 Partition에만 전달되기 때문에, Key 레벨의 순서 보장이 가능하다. -> 멀티 Partition 사용 가능 및 처리량 증가
- 운영 중에 Partition의 개수가 변경이 되면, Kafka는 Partition의 개수로 Key 값에 Hash를 적용하기 때문에 같은 Key임에도 동일한 Partition에 배정받지 못해 순서가 보장되지 않는 경우가 발생할 수 있다. -> Consumer 처리에서 문제 발생
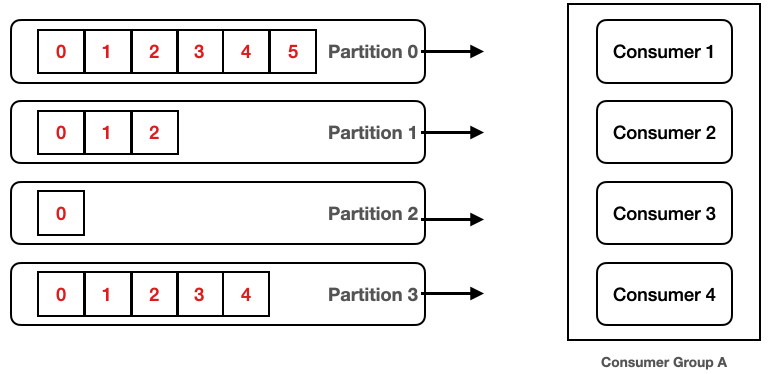
- Cardinality: 특정 데이터 집합에서 유니크한 값의 개수
- Key Cardinality는 Consumer Group의 개별 Consumer가 수행하는 작업의 양에 영향을 받는다.
- Key 선택이 잘 못되면 작업 부하가 고르지 않을 수 있다. -> 위의 Consumer 1은 데이터가 많지만, Consumer 3은 데이터가 적어 작업의 부하가 고르지 못하다.
- Key는 단순히 String, Integer일 필요가 없어, Json, Avro 같은 복잡한 객체를 사용해도 된다.
- Key를 잘 선택해서 Partition 전체에 Record가 고르게 분포하도록 하는 것이 좋다.
* Consumer Failure
- Consumer는 주어진 Topic에서 0개 이상의 많은 Partition을 사용할 수 있다.
- 따라서, Consumer에 장애가 발생하면 ReBalancing이 이루어지고 다른 Consumer가 장애가 발생한 Consumer의 역할을 대신한다.
'Kafka' 카테고리의 다른 글
| [Kafka] Replication (1) (0) | 2022.10.12 |
|---|---|
| [Kafka] Consumer (2) (0) | 2022.10.11 |
| [Kafka] Producer (2) (0) | 2022.10.09 |
| [Kafka] Producer (1) (0) | 2022.10.09 |
| [Kafka] Apache Kafka란? (0) | 2022.10.07 |



