검색 엔진 시스템이란 컴퓨터 시스템에 저장된 정보(문자 정보, 오디오 정보, 이미지, 3D 그래픽 등...) 찾기를 도와주도록 설계된 정보 검색 시스템이다.
검색 시스템의 사례
오프라인 - 파일 검색, 데스크탑 검색
검색 서비스 - 웹 검색, 이미지 검색, 비디오, 오디오 검색 등...
인터페이스형 - 인공지능 개인비서, 지도형(카카오 맵, 배달앱...)
추론형 - Zillow, Redfin
- 데이터들을 통합하여 추론을 만들어 검색을 도와준다.
SQL과 비교
많은 쇼핑몰들과 여러 가지 기본 웹 사이트들은 SQL로 검색 기능을 제공하고 있다.
굳이, 검색 엔진을 도입하는 이유는? -> Scale, Speed, Usefulness
차이점
SQL
- Transaction을 위해서 제작된 데이터베이스이다. -> ACID를 제공해주는 큰 장접을 가지고 있다.
- Transaction이 Commit이 되면 이루어졌다는 것이 확실해지고 모두가 정확한 데이터를 가지고 있는 것을 알 수 있다.
- B-Tree나 Linear Scan을 사용한다. -> 데이터 사이즈가 커질수록 속도가 느려진다.
- O(n), O(log n)의 시간이 소요된다.
- realTime 데이터를 제공할 수 있다.
- 고급 검색 결과, 랭킹 등의 기술을 도입하기 힘들다. -> Transaction Nature를 위해서 만들어진 데이터 베이스이기 때문에 이 위에 고급적인 텍스트 Manipulation, 오디오 이미지 프로세싱 등을 추가하기 매우 벅차다.
- 사용자 요청, 트래픽이 증가하면 더 비싼 cost가 요구된다.
- Consistency를 축으로하는 서비스이다.
NoSQL
- SQL과 달리 ACID를 제공하지 않는다.
- SQL보다 더 나은 PartitionTolerance, Availability를 제공한다.
검색엔진
- ACID를 제공하지 않는다. ->결과가 Stale 해지고 없는 결과가 나올 수 있으며, 변경이 반영되는데 오랜 시간이 걸릴 수 있다.
- 데이터 사이즈가 커지더라도 상관 없이 결과를 매우 빠르게 응답할 수 있는 강력한 장점을 가진다.
- O(1)의 시간이 소요된다.
- 데이터가 추가되고 인덱싱되면 오랜 시간이 소요된다.
- 무제한 Advanced Search Feature를 추가할 수 있다.
- 트래픽이 늘더라도 부하 속도는 일정하게 유지된다.
- 전문화된 NoSQL의 유형이다.
검색 엔진 특징
검색 엔진 기술의 핵심은 인덱싱이다. -> 검색 엔진이 효율적이고, 빠른 이유
색인
색인이란, 특정한 데이터가 어느 위치에 있는지 미리 저장해두어 검색 시에 빠른 속도로 찾을 수 있도록 하는 것. -> 국어 사전의 가나다순의 첫 번째 단어마다 갈피를 만들어서 우리가 찾는 단어를 빠르게 찾을 수 있도록 하는 방법과 유사하다.
역색인
일반적인 색인의 단점은 데이터의 위치를 순서대로 기억하기 때문에 매우 많은 데이터가 존재하는 곳(100만 개)에서 특정 단어가 들어간 데이터를 찾는다고 하면, 1번부터 100만 번까지 검색을 진행한다.
역색인이란, 데이터 색인 시에 단어를 기준으로 색인을 수행하는 것이다.
예를 들어, 홍길동 # 1, 2, 3 -> 이렇게 색인을 진행하여 1번, 2번, 3번 문서에 홍길동이 있다는 것을 파악하고 해당 문서만 검색을 진행할 수 있다.
검색 기술의 기본 Architecture

- 검색을 하고 싶은 빅데이터 소스
- 빅데이터를 가공하여 필요한 키워드들과 주석, 추가 데이터들을 첨부하는 시스템 -> 수집 / 주석 시스템
- 위 과정에서 생성된 데이터들은 주석 데이터들을 저장하는 데이터 저장소에 저장된다.
- 저장된 주석 데이터들은 인덱싱 시스템이 데이터를 읽고 색인을 생성한다.
- 이렇게 생성된 색인은 색인들로 저장된다. -> 저장된 색인들은 다른 시스템들이 사용하기 편하게 분리되어 저장될 수 있다.
- 저장된 색인은 컬렉션 분석 시스템들이 사용한다.
- 사용자가 쿼리를 요청하면 쿼리 처리 시스템이 시스템이 이해하기 쉽게 재분석한다.
- 분석된 명령은 Sorting, Ranking 시스템이 여러가지 컬렉션 분석 시스템에 보내게 된다.
- 컬렉션 분석 시스템은 분산된 색인들 사이에서 필요한 정보를 추출하여 Sorting / Ranking 시스템에 전달한다.
- Soring / Ranking 시스템은 결과들을 Merge하여 결과를 응답한다.
Information Retrieval
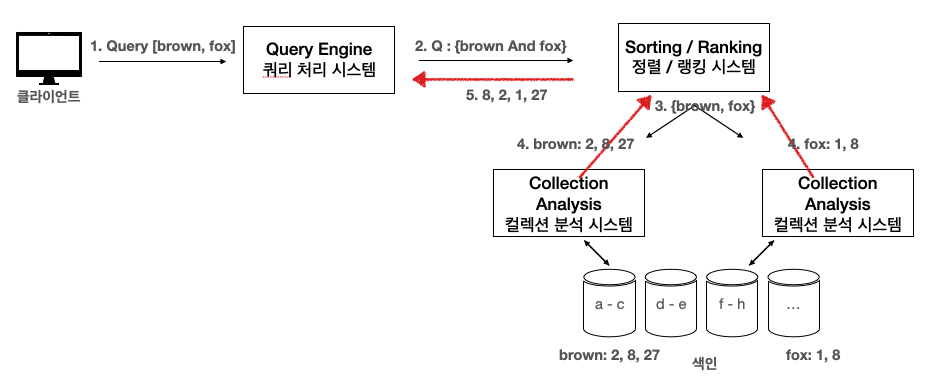
- 사용자의 Query를 쿼리 처리 시스템에서 시스템이 알아볼 수 있도록 변형한다.
- Sorting / Ranking 시스템은 해당 단어들이 있을 수 있는 분산 컬렉션 분석 시스템에 보낸다.
- 색인들은 Topological Sorting 방식으로 정렬되어 있기 때문에 Sorting / Ranking 시스템은 어느 컬렉션 분석 시스템에 해당 쿼리를 전달해야 하는 지 알고 있다.
- brown, fox를 가지고 있는 컬렉션 분석 시스템은 이 단어들을 가지고 있는 문서들을 다시 Sorting / Ranking 시스템으로 보내준다.
- Sorting / Ranking 시스템은 받은 결과를 하나로 뭉쳐서 쿼리 처리 시스템으로 보낸다.
- 쿼리 처리 시스템은 사용자가 보기 편한 방식으로 응답한다.
- 8페이지에 brown, fox가 동시에 존재하여 제일 먼저 반환해 줌으로써 8페이지에 제일 유용한 결과가 있다는 것을 알게 된다.
'Elastic' 카테고리의 다른 글
| [Elastic] 검색 랭킹 (0) | 2022.10.08 |
|---|---|
| [Elastic] 지식 그래프란? (0) | 2022.10.06 |
| [Elastic] Elastic Search란? (1) | 2022.10.05 |


