데이터가 흐르는 Event Streams를 받아 해당 데이터를 필요로 하는 곳으로 전송해주는 시스템이다. 한마디로, 움직이는 데이터를 처리하는 플랫폼(Event Streaming Platform)
- Event: 서비스에서 일어나는 모든 데이터를 의미한다.
- 빅데이터의 특징을 가진다. -> 서비스 모든 영역에서 광범위하게 발생하기 때문에 대용량의 데이터가 발생한다.
- Ex) 웹 사이트에서 무언가를 클릭하는 것, 위치 정보, 고객 정보 등...
- Event Streams: 연속적인 많은 Event들의 흐름
Kafka 주요 특징
1. Event Stream을 안전하게 전송한다. (Publish & Subscribe)
2. Event Stream을 디스크에 저장한다. (디스크에 저장하면서 매우 빠른 속도의 데이터 전송을 지원한다.)
3. Event Stream을 분석 및 처리
4. 타 플랫폼에 비해 월등한 처리량을 제공한다.

Kafka 용도
1. Messaging System
2. IOT 디바이스로부터 데이터 수집
3. 애플리케이션에서 발생하는 로그 수집
4. Realtime Event Stream Processing (이상 감지)
5. DB 동기화 (MSA 기반의 분리된 DB간 동기화)
6. 실시간 ETL (추출, 변환, 적재)
Kafka 주요 요소

* Topic

- Kafka 안에서 메시지가 저장되는 장소, 논리적으로 표현됨
- Partition: Commit Log를 의미하며, 하나의 Topic은 하나 이상의 Partition으로 구성된다 -> 병렬 처리(Throughput 향상)를 위해서 다수의 Partition 사용
- 다수의 Partition을 사용하는 이유: 병렬처리로 처리량을 향상 시키기 위해서
- 다수의 Partition을 사용하는 이유: 병렬처리로 처리량을 향상 시키기 위해서
- Segment: Event가 저장되는 실제 물리 File
- Segment File이 지정된 크기보다 크거나 지정된 기간보다 오래되면 새 파일이 열로기 Event는 새 파일에 추가된다.
- Segment File이 지정된 크기보다 크거나 지정된 기간보다 오래되면 새 파일이 열로기 Event는 새 파일에 추가된다.
** Topic 생성 시 Partition 개수를 지정하며, 개수 변경은 가능하나 운영 시에는 변경을 권장하지 않는다.
** Topic 내의 Partition들은 서로 독립적이다.
** Partiton에 저장된 데이터는 변경이 불가능하다.
** Partition에 Write되는 데이터는 맨 끝에 추가되어 저장된다.
** Segment들이 너무 커지는 것을 방지하기 위해 log.segment.bytes(default 1 GB), log.roll.hours(default 168 hours)를 설정하여 기존 파일을 종료하고 새로운 파일에 작업을 진행한다.
* Producer
- Event를 생산(Produce)해서 Kafka의 Topic으로 전송하는 애플리케이션
* Consumer
- Topic에 저장되어 있는 Event를 가져와서 소비(Consume)하는 애플리케이션
* Consumer Group
- Topic의 Event를 사용하기 위해서 협력하는 Consumer들의 집합
- Consumer Group 내의 Consumer들은 협력하여 Topic의 Event를 분산 병렬 처리한다.
* Commit Log

- 추가만 가능하고 변경이 불가능한 데이터 구조로 Event는 항상 로그 끝에 추가되고 변경되지 않는다.
- 0, 1, 2, ..., n을 Offset이라고 한다. -> Event의 위치
- LOG-END_OFFSET: 마지막 Write Offset
- CURRENT-OFFSET: 마지막으로 읽고 처리한(Commit) 위치
** Producer와 Consumer는 서로 알지 못하고, Producer와 Consumer는 각각 고유의 속도로 Commit Log에 Write 및 Read 수행 -> 해당 이유로 인해 LOG-END-OFFSET과 CURRENT-OFFSET의 차이인 Consumer Lag이 발생할 수 있다.
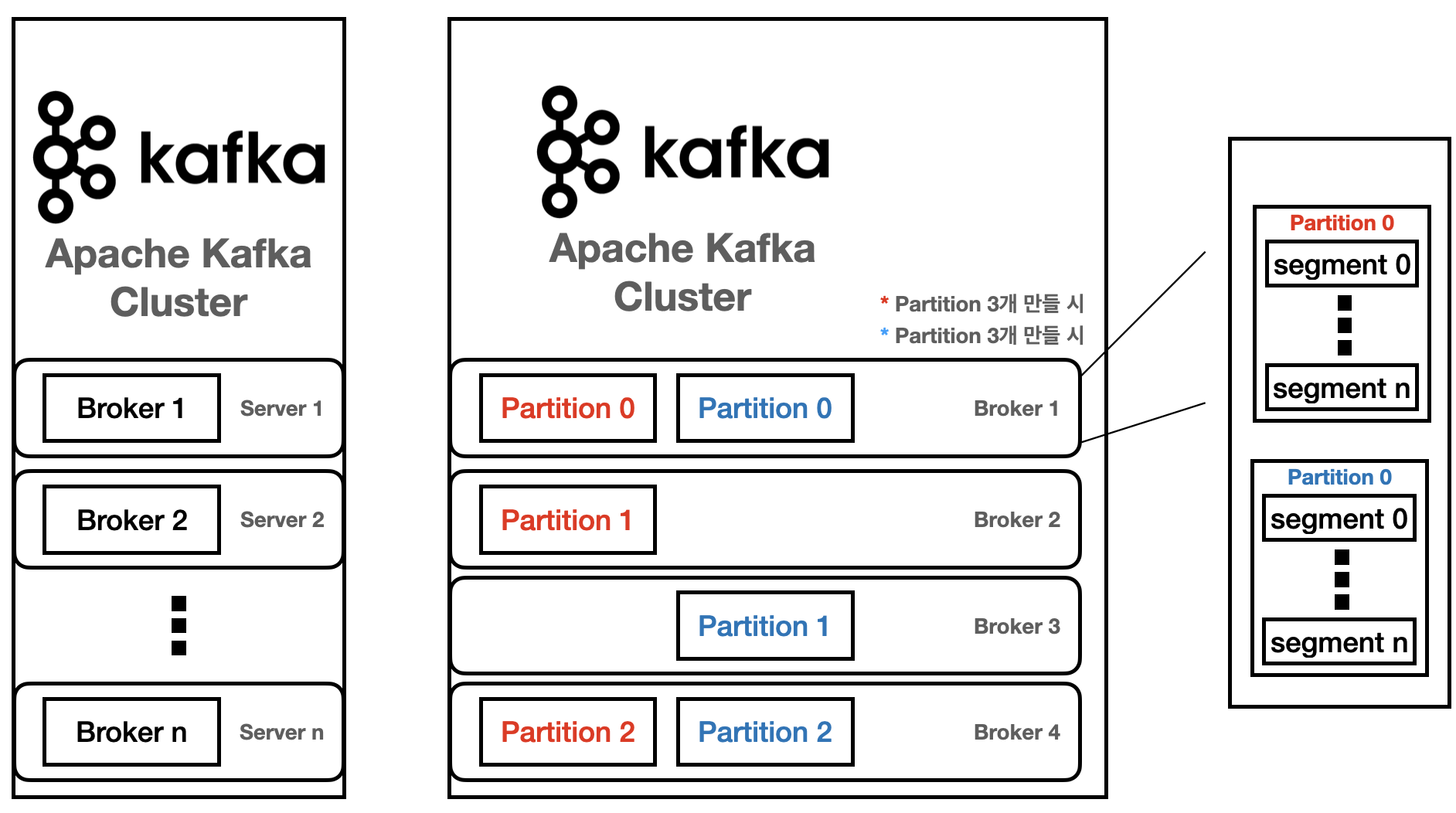
* Topic은 생성 시 Partition의 개수를 지정하고, 각 Partition은 Broker들에 분산되면 Segment File들로 구성된다.
* Partition 당 오직 하나의 Segment가 활성화 되어 있다. -> 데이터가 계속 쓰여지고 있는 중
* Broker, Zookeeper
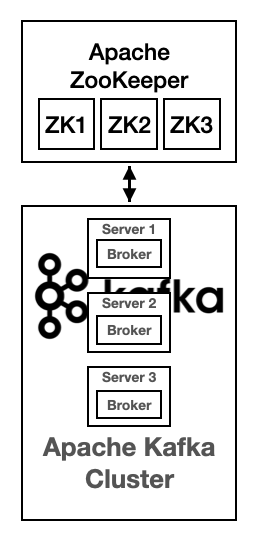
Broker
- Kafka Server라고 부르기도 한다.
- Partition에 대한 Read 및 Write를 관리하는 소프트웨어
- Topic 내의 Partition 들을 분산, 유지 및 관리
- Topic의 일부 Partition들을 포함 -> Topic 데이터의 일부분을 가지고 있을 뿐, 데이터 전체를 가지지는 않는다.
- ID로 식별한다.
- Client는 특정 Broker에 연결하면 전체 클러스터에 연결된다. -> Client가 Broker에 연결되면 Broker는 모든 Broker의 리스트를 응답해준다.
- 최소 3대 이상의 Broker를 하나의 Cluster로 구성해야 한다. -> 안정성을 위해 4대 이상을 권장한다.
- broker ID와 Partition ID 간에는 아무런 관련이 없다.
- Topic을 구성하는 Partition들은 여러 Broker 상에 분산된다.
Zookeeper

- Broker를 관리하는 소프트웨어
- 변경사항에 대해 Kafka에 알린다. -> Topic 생성/제거, Broker 추가/제거 등...
- Kookeeper 없이 Kafka는 동작하지 않는다.
- Zookeeper는 홀수의 서버로 작동되게 설계되어 있다. (최소 3, 권장 5) -> Quorum 기반 알고리즘(합의체가 의사를 진행시키거나 의결을 하는데 필요한 최소한의 인원 수(과반 이상))을 기반으로 하고 있고, 예상치 못한 장애가 발생해도 분산 시스템의 일관성을 유지시키기 위해서
- Leader와 나머지 서버는 Follower로 역할이 나뉜다.
- Zookeeper 서버의 클러스터를 Ensemble이라 한다.
'Kafka' 카테고리의 다른 글
| [Kafka] Replication (1) (0) | 2022.10.12 |
|---|---|
| [Kafka] Consumer (2) (0) | 2022.10.11 |
| [Kafka] Consumer (1) (0) | 2022.10.10 |
| [Kafka] Producer (2) (0) | 2022.10.09 |
| [Kafka] Producer (1) (0) | 2022.10.09 |



